
안녕하세요
블레이즈 테크노트의 블레이즈입니다.

지난 포스트에서 Seq2Seq 모델을 살펴봤습니다.
NLP 시퀀스 투 시퀀스 신경망 기계 번역 모델(Seq2Seq Neural Machine Translation) 기초
안녕하세요 블레이즈 테크 노트의 블레이즈 입니다. 지난 포스트에서 RNN 순환 신경망을 공부했습니다. 이번에는 RNN을 활용한 시퀀스 투 시퀀스 신경망 기계 번역 모델에 대해서 알아보고자 합
blazetechnote.tistory.com
이 시퀀스 투 시퀀스 모델은 단점이 있었습니다.
바로 인코더에서 디코더로 넘어가는 context 벡터가 전체 모델의 보틀넥이 되어버린 다는 점입니다.
왜냐하면 인풋의 모든 정보를 context 벡터에 다 담아야 하기 때문에
이 과정에서 정보가 손실되기도 하고 처리 시간이 오래 걸리기도 합니다.
뿐만 아니라 인풋의 앞쪽 단어가 가지고 있던 정보는 점점 흐려지고
인풋의 뒤쪽 단어가 가지고 있던 정보가 상대적으로 진하게 담긴다는 단점이 있었습니다. (Vanishing Gradient)

이 Seq2Seq 신경망 기계 변역의 효율을 높여준 기술이 Attention 매커니즘입니다.
어텐션 메커니즘은 먼저 LSTM의 단점인 Vanishing Gradient를 해소합니다.
기존의 Seq2Seq 모델이 맨 마지막 hidden state 만 디코더로 넘겼다면
이제는 모든 hidden state를 전부 decoder로 넘깁니다.

이런 식으로 각 단계의 히든 스테이트를 모두 참고합니다.

두 번째로는 디코더가 넘겨받은 hidden states에 어떤 처리를 한다는 점인데 이를 scoring이라고 합니다.
scoring은 결국 디코더가 decode할 때 input중에서 연관이 있는 부분에 가중치를 매기는 과정입니다.
예를 들어서 "저 새가 예쁘다" 라는 말을 번역할 때 That bird is 다음 단어를 생성중이라면 한국어의 '예쁘다'라는 단어에 가중치를 줘서 "pretty"를 생성할 수 있다는 의미입니다.
이 Attention Scoring에 대해선 논문 별로 아래에 자세히 설명했으니
여기선 이런 단계가 있다는 정도로만 이해하고 넘어가도록 하겠습니다.
Attention 프로세스를 잘 설명한 동영상이 있어서 첨부합니다.
그러니까 4번째 디코더의 hidden state를 만들기 위해서 인코더의 모든 hidden state를 전부 참조합니다.
그러나 모든 hidden state를 동일한 비중으로 참조하는 것이 아니라 scoring을 통해 연관이 높은 단어에게 높은 비중을 부여합니다.
softmax 함수를 취합니다.(softmax는 합이 1이 되게끔 하는 것입니다.)
이를 통해 연관이 높은 단어는 강조하고 연관이 거의 없는 단어는 약화시킬 수 있습니다.
이렇게 해서 모든 디코더의 hidden state를 만들 때마다
그에 해당하는 context vector를 새롭게 만드는 방식이 어텐션 매커니즘입니다.
그림으로 나타내면 아래의 그림과 같습니다.

그림을 보시면 모든 hidden state를 더해서 context vector를 만들어냅니다.
이 context 벡터는 아웃풋 시퀀스의 모든 인스턴스마다 새롭게 만들어집니다.
그러한 이유는 HS1, HS2, HS3가 그냥 더해지는 것이 아니라
어떤 아웃풋이냐에 따라 다른 a1, a2, a3가 곱해지기 때문입니다.
어텐션의 개념을 가장 처음 제안한 Bahdanau et al., 2014 의 아키텍쳐를 살펴보면 아래와 같습니다.
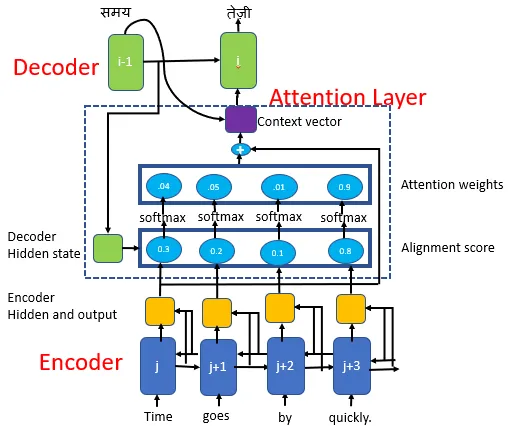
Seq2Seq 모델에서는 인코더의 마지막 hidden state가 Context vector가 되었습니다.
하지만 이제는 모든 시점에서 context vector를 계산합니다.
- 그림에서는 decoder의 i-1 단계에서 i 단계로 넘어갈 때 context vector를 구하는 모습이 나타나 있습니다.
각 context vector를 구할 때
Bahdanau et al., 2014 의 논문에서 s_t = Decoder(y_t-1, s_t-1, c_t) 를 통해 계산합니다.
여기서 c_t 를 어떻게 구할 것인지가 scoring과정입니다.
scoring에 대해서는 다양한 방법이 있기 때문에 잠깐 수식적인 측면을 최대한 줄이고 개념적으로 설명해보겠습니다.

scoring이란 attention score(alignment score라고도 한다)를 구하는 과정입니다.
이 attention score는 직전에 디코더에서 구한 hidden state s_t-1과
각 인코더의 hidden state h_j가 얼마나 유사한지 확인하는 과정입니다.
물론 구체적인 방식은 a 함수에 따라 달라지겠죠.
a 함수는 alignment model이라고도 하고 attention function이라고도 부릅니다.

다음으로 softmax 함수를 취해 attention score를 attention weight로 변환해줍니다.
어떻게 보면 합이 1이 되게끔 하여 확률화 하는 거라고 볼 수도 있겠습니다.
그리고 이 확률과 각각의 값을 곱하여 가중평균을 구해서 c_t를 계산합니다.

논문에는 아래와 같이 나와 있습니다. 그러니까 α_t-1,j는s_t-1의 관점에서 봤을 때
h_j가 다음 스텝인 s_t를 만들어내는 데에 얼마나 중요한 지 나타내는 확률과 같습니다.
The probability αij , or its associated energy eij , reflects the importance of the annotation hj with respect to the previous hidden state si−1 in deciding the next state si and generating yi. Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed- length vector. With this new approach the information can be spread throughout the sequence of annotations, which can be selectively retrieved by the decoder accordingly.
한편, Luong et al., 2015 은 약간 다른 attention scoring을 제시했습니다.
기본적으론 동일하지만 energy를 구하는 방법과 순서가 약간 다른데요,
s_t = Decoder(y_t-1, s_t-1) 을 통해 디코더의 hidden state를 먼저 구합니다.
그리고 이렇게 구한 s_t를 이용해
c_t = a(s_t, h_j) 를 계산합니다.
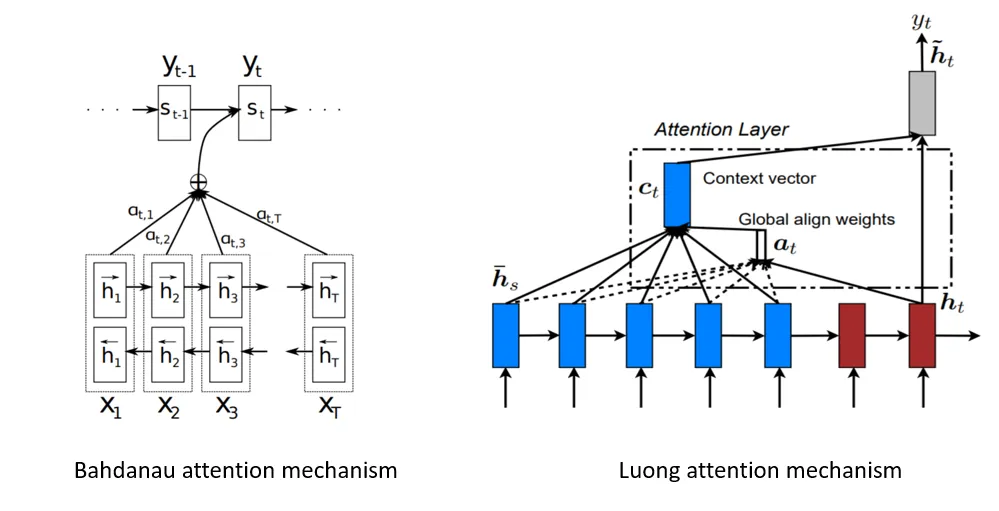
Luong 모델을 보면 디코더의 h_t-1을 이용해 h_t를 먼저 만듭니다.
그리고 그 다음 인코더의 h_j와 어텐션 스코어링을 통해 context vector c_t를 만듭니다.
그렇게 만든 context vector와 h_t를 가지고 하이퍼볼릭 탄젠트 함수를 이용해 정규화를 시켜서 결과값을 구합니다.

결과적으로 Attention Mechanism은 Seq2Seq 모델에서
크기가 정해져있는 context vector로부터 야기되는 문제를 해결한 방법입니다.
이때, context vector를 단순히 하나로 압축해서 만들지 말고
인코더의 모든 hidden state를 활용하겠다는 발상입니다.
그리고 인코더의 hidden state 중에서 어떤 부분을 더 중요하게 참고해야 할 지 판단하는 과정에서
디코더의 RNN의 hidden state와 유사한지를 따져서 중요성을 판단하는 attention scoring을 진행합니다.
attention score가 다 매겨지고 나면 softmax 함수를 이용해 합이 1이 되게 만들어서
이 수치를 확률로 해석할 수 있도록 합니다.
이를 통해 가중합을 구하고 다음에 나올 단어 중 가장 확률이 높은 단어를 output으로 산출하는 모델입니다.
감사합니다.
블레이즈 테크노트
Reference :
Bahdanau et al., 2014 Luong et al., 2015
https://towardsdatascience.com/day-1-2-attention-seq2seq-models-65df3f49e263
https://towardsdatascience.com/sequence-2-sequence-model-with-attention-mechanism-9e9ca2a613a
https://towardsdatascience.com/sequence-2-sequence-model-with-attention-mechanism-9e9ca2a613a
'머신러닝(Machine Learning)' 카테고리의 다른 글
| NLP 트랜스포머 두 번째, 포지셔널 인코딩(Positional Encoding) 알아보기 (0) | 2023.07.25 |
|---|---|
| NLP 트랜스포머 첫 번째, RNN에서 트랜스포머로 (0) | 2023.07.24 |
| NMT(인공 신경망 기계 번역) Seq2Seq 에서 어텐션 메커니즘까지 정리 (0) | 2023.07.14 |
| NLP 시퀀스 투 시퀀스 신경망 기계 번역 모델(Seq2Seq Neural Machine Translation) 기초 (0) | 2023.07.11 |
| 머신러닝(ML) 순환신경망(Recurrent Neural Network) 기초 (0) | 2023.07.10 |



