
안녕하세요
블레이즈 테크노트
블레이즈 입니다.

트랜스포머 두 번째 이야기에서 포지셔널 인코딩(Positional Encoding)에 대해서 알아봤습니다.
https://blazetechnote.tistory.com/entry/NLP-트랜스포머-두-번째-포지셔널-인코딩Positional-Encoding-알아보기
이번 포스팅에서는 포지셔널 인코딩을 거친 input이 다음으로 거치는
Self Attention Layer에 대해서 알아보도록 하겠습니다.
이 셀프 어텐션은 트랜스포머 아키텍쳐 중 핵심이라고 할 수 있습니다.
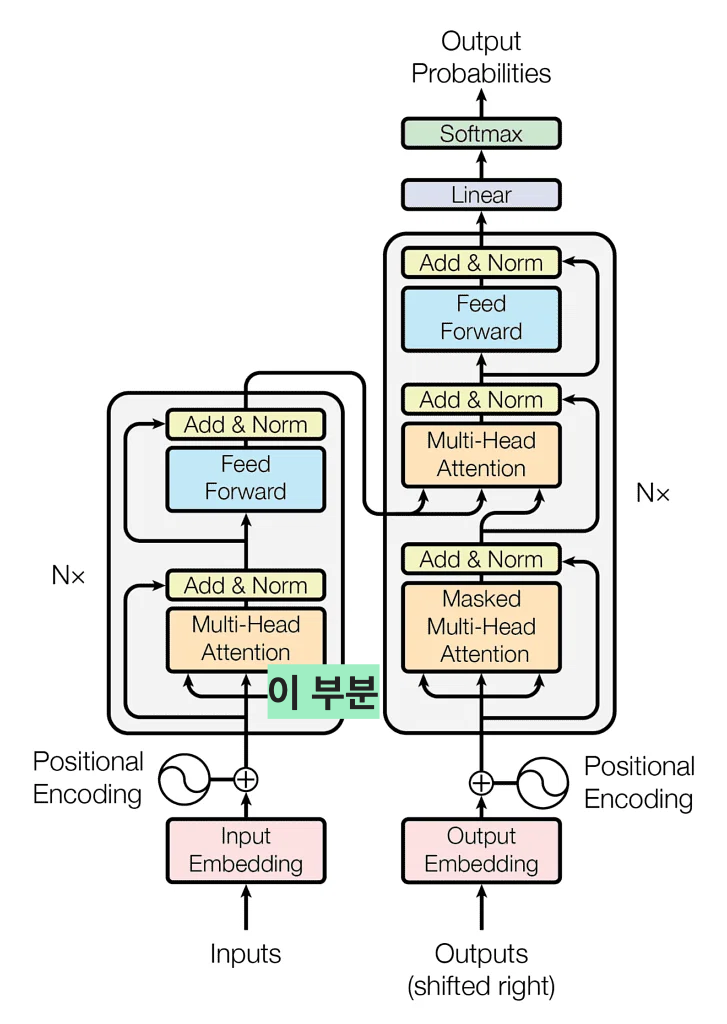
셀프 어텐션을 설명하기에 앞서 어텐션 메커니즘을 조금 일반화 해보겠습니다.
어텐션 메커니즘에 대한 자세한 설명을 아래의 포스트를 참고해주세요.
https://blazetechnote.tistory.com/entry/NMT인공신경망-기계-번역-어텐션Attention이란-기초-설명
NMT(인공신경망 기계 번역) 어텐션(Attention)이란? 기초 설명
안녕하세요 블레이즈 테크노트의 블레이즈입니다. 지난 포스트에서 Seq2Seq 모델을 살펴봤습니다. https://blazetechnote.tistory.com/entry/NLP-시퀀스-투-시퀀스-신경망-기계-번역-모델Seq2Seq-Neural-Machine-Transl
blazetechnote.tistory.com
어텐션 메커니즘은
내가 참고로 하는 S_t (디코더에서 바로 직전 출력값) 가 있고
인코더의 h_j 중 어느 것을 참조하면 좋을까~ 하는 질문이었습니다.
이 때, 우리는 S_t 와 h_j의 벡터 값의 유사도를 측정했습니다.
잠깐 복습을 위해 그림을 만들어왔습니다.
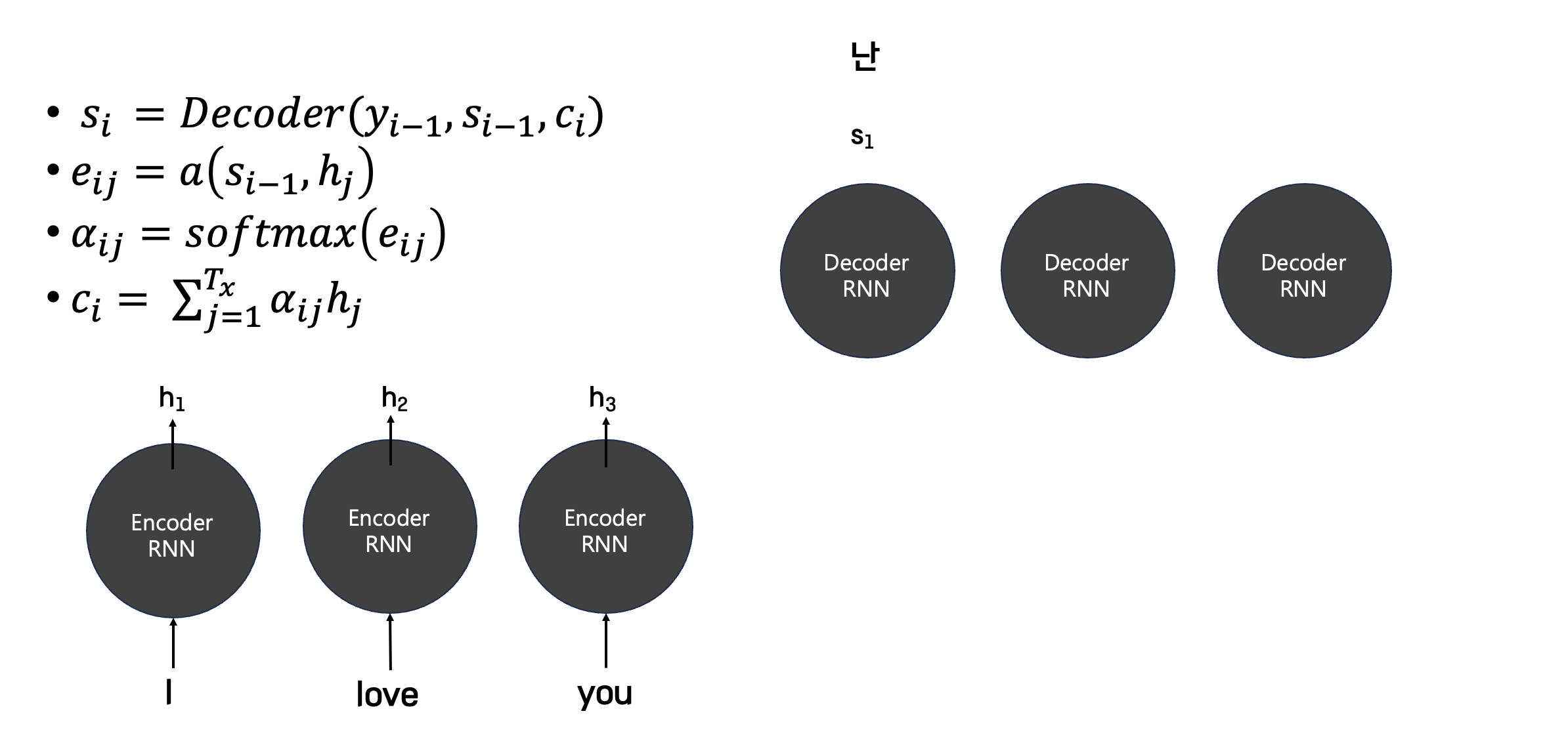
먼저 인코더의 모든 hidden state 와의 에너지 값을 구합니다.

에너지 값을 구하면 softmax로 확률화를 시킨 후,
다시 각 hidden state와의 가중합을 구해서 context vector를 구합니다.

이렇게 구한 context vector를 활용해 디코더의 hidden state를 구합니다.
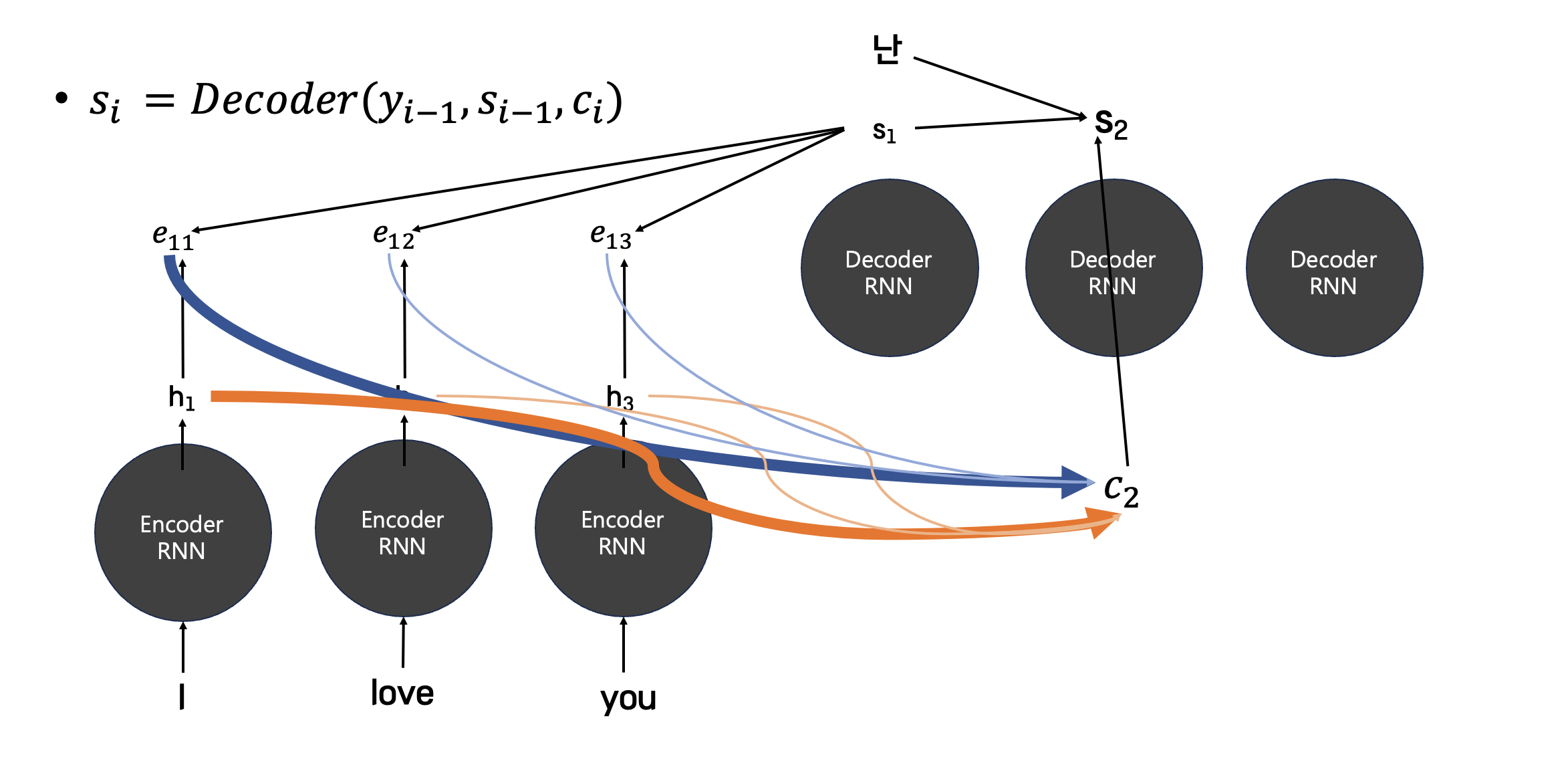
최종적으로 "널" 이라는 단어를 구하게 되는 것입니다.

어텐션 메커니즘을 일반화 해보면 우리가 기준으로 생각하는 것(S_t :Q, query)이 있고
비교할 대상의 이름(h_j : K, key)이 있으며
그 각각의 대상은 값(V, value)를 가지고 있습니다.
이렇게 어텐션 메커니즘에서
유사도를 비교하는 기준이 되는 벡터를 Query 벡터라고 합니다.
이 쿼리 벡터는 백과사전에서 우리가 찾기를 원하는 단어에 해당된다고 생각할 수 있습니다.
이 Query 벡터와 비교를 하는 대상을 Key 벡터라고 합니다.
이 키 벡터는 백과사전에 뜻이 적혀있는 모든 단어라고 생각할 수 있습니다.
다음으로 Value 벡터는 Key 벡터의 의미에 해당합니다.
백과사전의 비유를 들면 Key 단어에 해당하는 뜻이 Value 벡터가 될 것입니다.

예를 들어서 "I love my dog" 라는 문장에서
I love my dog 네 개의 단어를 쪼갰습니다.
임베딩과 포지셔널 인코딩을 거쳐서
I ----> [1, 0, 0, 0]
love ----> [0, 1, 0, 0]
my ----> [0, 0, 1, 0]
dog ----> [0, 0, 0, 1]
과 같이 변환되었다고 가정해보겠습니다.
저는 먼저 [1, 0, 0, 0] 벡터에 대해서 다른 모든 벡터와의 유사도를 구해야 합니다.
그렇다면 이때 [1, 0, 0, 0] 는 Query 벡터가 된 것입니다.
그리고
[1, 0, 0, 0] 과 [1, 0, 0, 0] 의 유사도를 구할 땐 [1, 0, 0, 0] 가 Key 벡터
[1, 0, 0, 0] 과 [0, 1, 0, 0] 의 유사도를 구할 땐 [0, 1, 0, 0] 가 Key 벡터
[1, 0, 0, 0] 과 [0, 0, 1, 0] 의 유사도를 구할 땐 [0, 0, 1, 0] 가 Key 벡터
[1, 0, 0, 0] 과 [0, 0, 0, 1] 의 유사도를 구할 땐 [0, 0, 0, 1] 가 Key 벡터가 된 것입니다.
정리하자면 우리는 임베딩 벡터로부터 세 개의 벡터, Query Key Value를 얻어야 합니다.
그렇다면 하나의 벡터로부터 세 개의 벡터를 얻어야 하는데 이것은 어떻게 구할 것이냐?
그것은 트레이닝 과정에서 구한 weight 행렬을 곱해서 구할 수 있습니다.
아래의 그림은 "Thinking Machines"라는 input을 처리하는 과정을 나타낸 그림입니다.
먼저 Thinking 이라는 단어 토큰이 x1 임베딩 벡터가 됩니다.
다음으로 x1 임베딩 벡터에
WQ 행렬을 곱해서 q1
WK 행렬을 곱해서 k1
WV 행렬을 곱해서 v1
를 만들 수 있습니다.
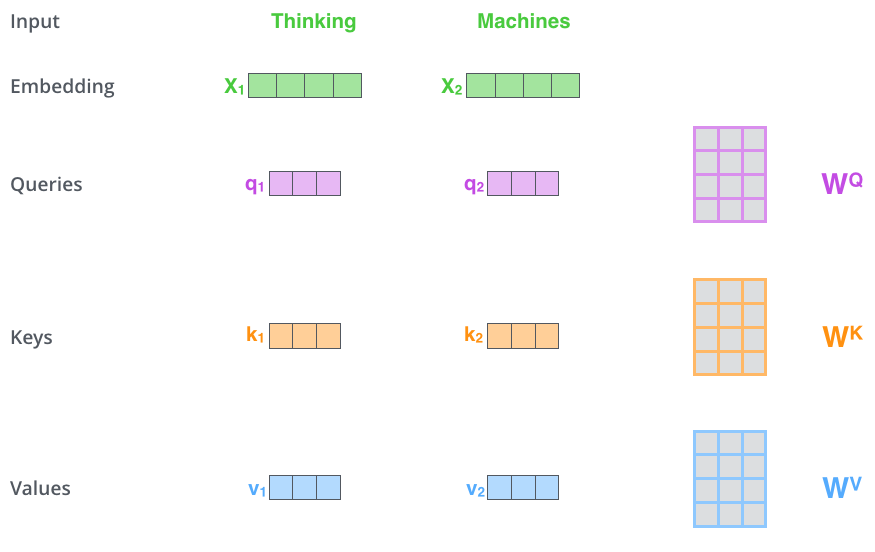
마찬가지로 x2 임베딩 벡터에
WQ 행렬을 곱해서 q2
WK 행렬을 곱해서 k2
WV 행렬을 곱해서 v2
를 만들 수 있습니다.
이렇게 만들어진 쿼리, 키, 밸류 벡터로 어텐션 스코어 Attention Score를 계산합니다.
어텐션 메커니즘에 대해서 공부했으니
Attention score를 구하는 것에 대해 간단하게만 언급해보자면
어텐션 스코어는 우리가 인코딩 하고자 하는 어떤 단어가
input내의 다른 단어와 얼마나 큰 영향를 주고 받는지,
Query 단어를 번역할 때 다른 단어(Key)에 어느 정도 집중해야 할지를 정하는 것입니다.
Attention Score를 구하는 과정에 대해서 소개를 해보겠습니다.
사실 Attention score를 구하는 계산 식의 종류는 여러가지가 있습니다.
Transformer를 제안했던 논문의 저자가 사용한 방식은 Scaled Dot-Prodect Attention 방식이므로
저도 이 계산식으로 attention score를 구하는 방법을 설명해보겠습니다.
아래의 그림에서 왼쪽을 보시면 Scaled Dot-Product Attention을 구하는 순서가 나와있습니다.

1단계.
Q와 K를 MatMul을 먼저 한다고 나와있습니다.
MatMul은 여기서는 내적이라고 보시면 될 것 같습니다.
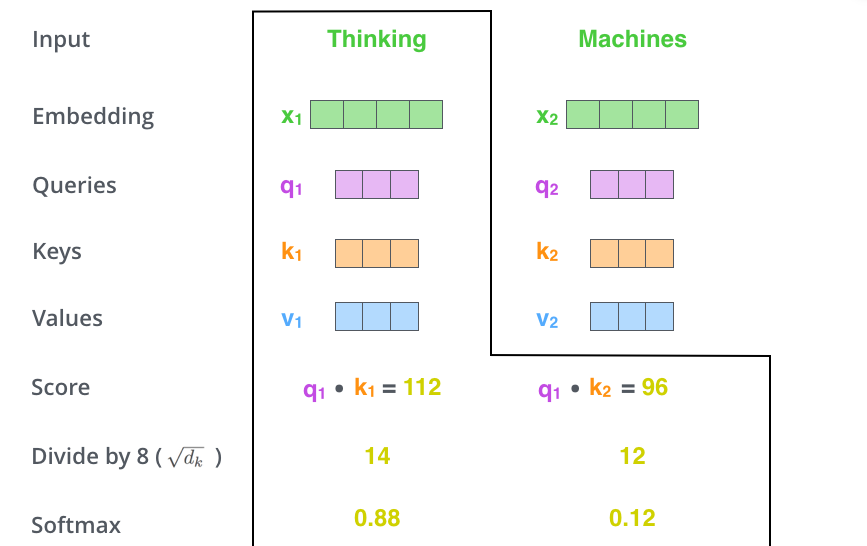
먼저 쿼리 벡터와 키 벡터를 내적합니다.
아래의 그림을 보면 q1과 k1를 내적한 값이 112이고 q1과 k2를 내적한 값이 96입니다.

2단계.
2단계는 Scale 단계입니다.
이렇게 구한 값을 key의 디멘션의 제곱근으로 나눠주는 걸 의미합니다.
논문에 의하면 이 방식이 효율적이라고 합니다.
논문에서 key 벡터의 차원이 64였으므로 우리는 이 값을 8로 나눠줍니다.
저희가 지금까지 한 것을 어텐션 계산식에서 확인해보면 softmax를 취하기 전 괄호 안쪽만 계산한 값입니다.

지금까지의 과정을 정리해보면 아래의 그림과 같습니다.
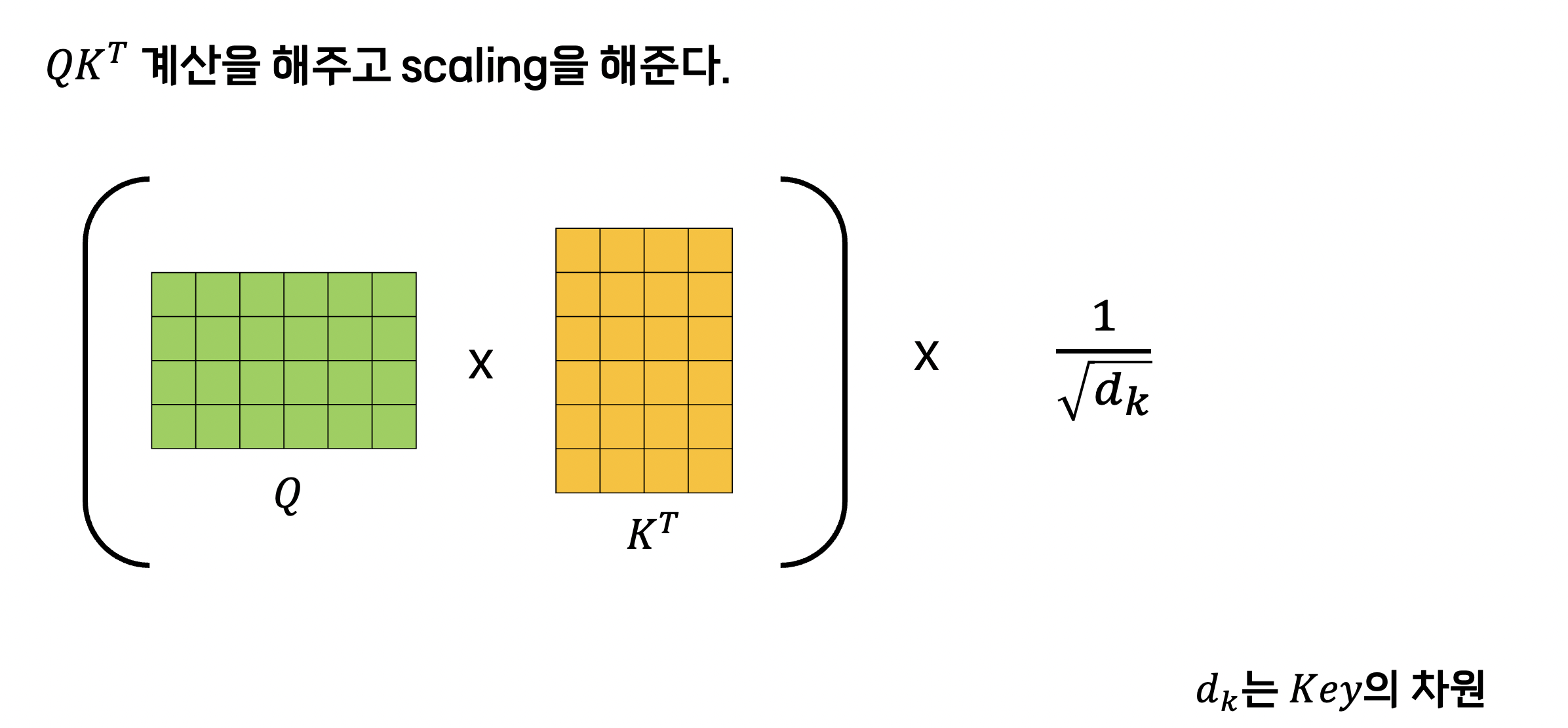
다음 단계는 뭘까요?
3단계.
3단계는 softmax를 취해주는 것입니다.
이 소프트맥스 함수에 대해서는 어텐션 메커니즘을 설명한 이전 포스팅에서도 한 번 설명했었는데요.
결국 이 소프트맥스 함수의 역할은 Query벡터와 Key벡터로 구한 점수를 확률로 변환시키는 것입니다.
소프트맥스 함수를 활용하면 모든 점수를 양수화시키고 모든 값의 합을 1로 만들 수 있습니다.
쿼리 벡터와 키 벡터의 내적을 통해 구한 두 벡터의 유사도의 정도는 소프트맥스 함수를 취하더라도 그대로 유지됩니다.
다시 말해, softmax 함수는 내적값의 상대적 크기를 유지한다는 의미입니다.
4단계.
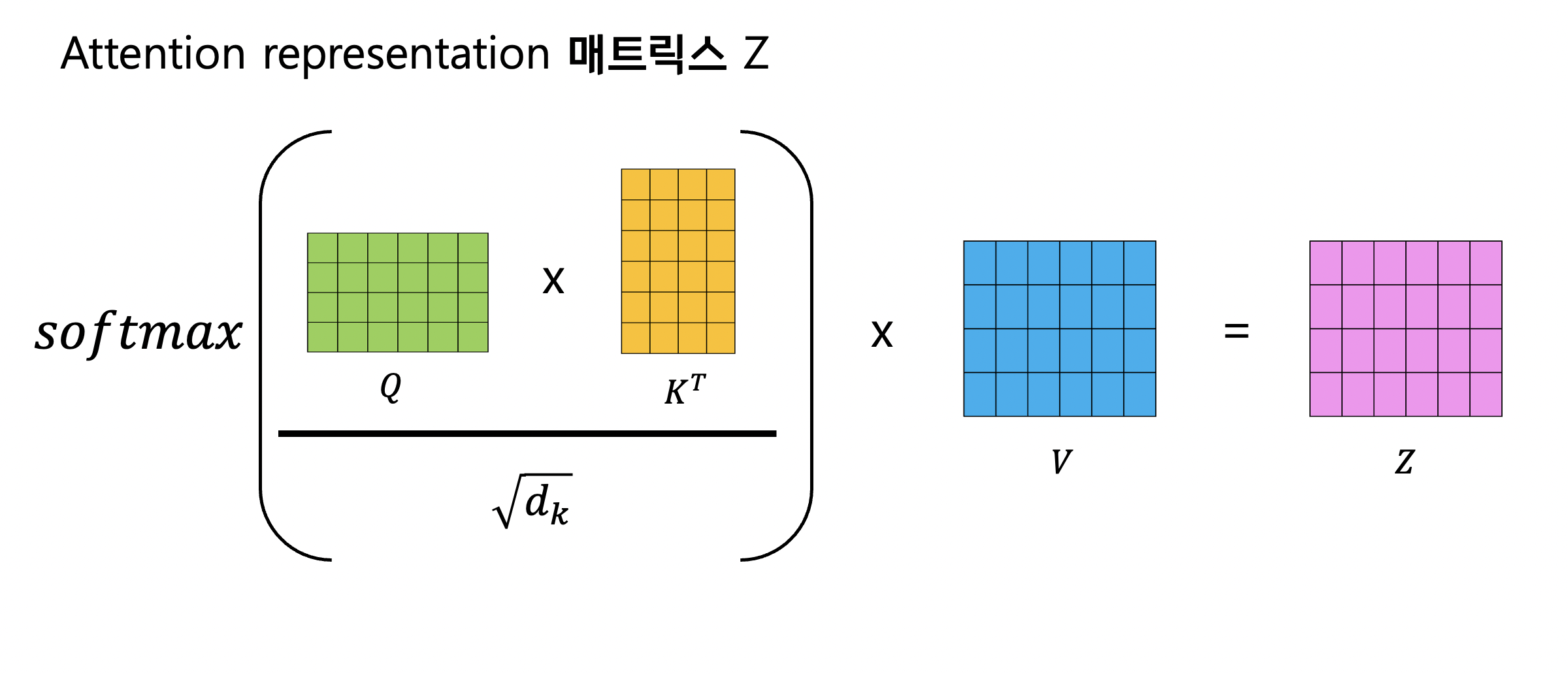
4단계는 softmax를 취해준 값을 모든 value 벡터와 곱해줍니다.
이 과정을 통해 우리는 어떤 value값에 집중하고 어떤 value 값을 무시할 지 결정할 수 있습니다.
아래의 그림에서 softmax 값이 낮은 v2는 그 의미가 흐려졌습니다.
다음으로는 이렇게 구한 값들을 모두 더하는 것입니다.

이렇게 각 단어에 대하여 z 값을 구하면 이제 다음 단계인 Feed Forward Neural Network로 넘어갑니다.
다만 약간의 차이점이 있다면
지금까지 살펴본 것처럼 행이 1인 벡터로 계산하는 것이 아니라
행렬 계산을 통해 한꺼번에 input 내 모든 단어를 계산한다는 점입니다.
아래의 그림이 이러한 계산과정을 나타낸 그림으로 지금까의 Self-Attention 과정을 살펴보고
자세한 매트릭스 계산은 다음 포스트에서 다뤄보도록 하겠습니다.
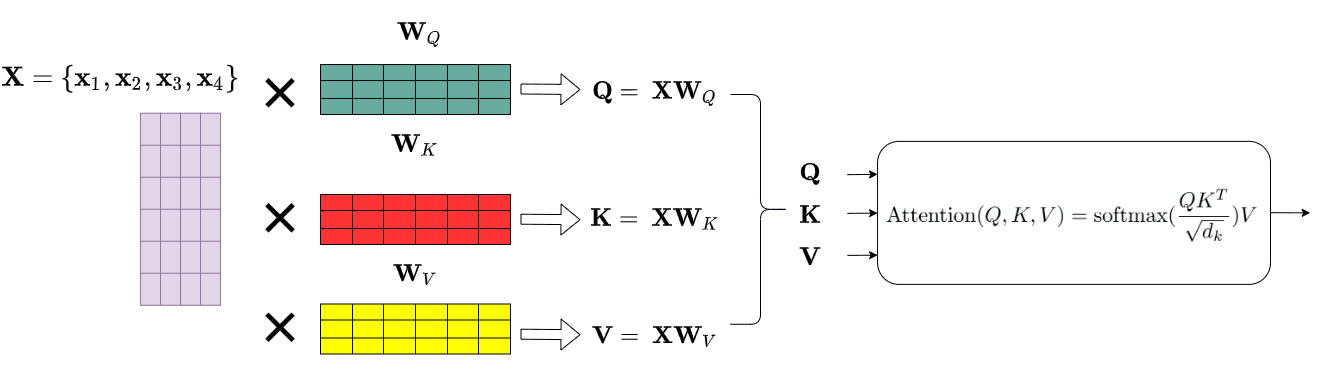
이 그림을 보시면 임베딩 매트릭스를 미리 훈련한 Weight 매트릭스와 곱해
Query, Key, Value 매트릭스를 생성합니다.
그리고 이 Query 매트릭스와 Key 매트릭스를 내적하고(트랜스포스 후 멀티플라이)
key의 차원의 제곱근으로 나눴습니다.
다음으로 softmax를 취하고 Value 매트릭스와 곱해서
최종적인 Attention 매트릭스를 얻었습니다.
'머신러닝(Machine Learning)' 카테고리의 다른 글
| NLP 트랜스포머 모델 데이터셋 wmt14 다운로드하기 (0) | 2023.08.05 |
|---|---|
| NLP 트랜스포머 네 번째, 멀티 헤드 어텐션 Multi-Head Attention 알아보기 (0) | 2023.08.01 |
| NLP 트랜스포머 두 번째, 포지셔널 인코딩(Positional Encoding) 알아보기 (0) | 2023.07.25 |
| NLP 트랜스포머 첫 번째, RNN에서 트랜스포머로 (0) | 2023.07.24 |
| NMT(인공 신경망 기계 번역) Seq2Seq 에서 어텐션 메커니즘까지 정리 (0) | 2023.07.14 |



