
안녕하세요
블레이즈 테크노트
블레이즈입니다.

지난 포스팅에서 트랜스포머에 대한 간단한 소개를 했습니다.
혹시 인트로가 궁금하시다면 아래의 포스팅을 참고해 주세요.
https://blazetechnote.tistory.com/entry/NLP-트랜스포머-첫-번째-RNN에서-트랜스포머로
앞으로 트랜스포머에 대해 조금씩 알아가 보도록 할 건데요
오늘은 트랜스포머의 특징 중 하나인 Positional Encoding부터 알아보려고 합니다.
아래의 그림이 트랜스포머 구조입니다.
그리고 제가 이 부분이라고 표시해놓은 부분이 Positional Encoding이 되는 부분입니다.

아래의 그림은 위 구조를 조금 더 단순하게 표현한 그림입니다.
이를 보시면 모든 단어가 Embedding Vector로 변환이 되고 나서
Positional Encoding 과정을 거친다는 걸 한 눈에 알 수 있습니다.

Seq2Seq 모델은 RNN을 활용했기 때문에 input이 순서대로 들어왔습니다.
input 문장을 순서대로 모델에 넣어주고 순서대로 output을 생성하는 형태였죠.
하지만 이러한 RNN을 제거하면서
트랜스포머 모델은 input을 한꺼번에 모델에 넣게 됩니다.
input을 한꺼번에 넣는다는 것은 병렬화가 가능하다는 뜻이고 모델의 훈련 시간을 감소시킬 수 있는 장점이 됩니다.
하지만 문장 내에서 단어의 위치 관계를 트랜스포머 모델이 알 수 없는 상황이 발생하죠.
이를 방지하기 위해서 Positional Encoding을 해줍니다.
Positional Encoding은 Encoding 할 때 입력값에 위치 정보를 담아 벡터에 추가하는 방식으로
각 단어가 어느 위치에 있었는지를 추가해줍니다.

간단하게 말하면 위 그림처럼 문장의 각 단어를 위치마다 번호매김 해주는 거라고 볼 수 있습니다.
조금 더 자세히 보자면 아래의 그림과 같이 각 임베딩 벡터(Embedding Vector)에 포지션 정보를 더해줍니다.
아래의 그림에서 벡터의 길이가 4로 표현되어 있는데 실제 트랜스포머 모델에서는 d_model = 512입니다.

이 때 위치 정보를 가지고 있는 positional vector는 여러 가지 조건을 만족해야 하는데
그 값이 너무 크지는 않으면서 위치가 다른
모든 경우에 대해 서로 다른 위치 벡터가 되어야 합니다.
이러한 특징을 잘 만족하는 함수로 논문의 저자는 사인과 코사인 함수를 채택했습니다.
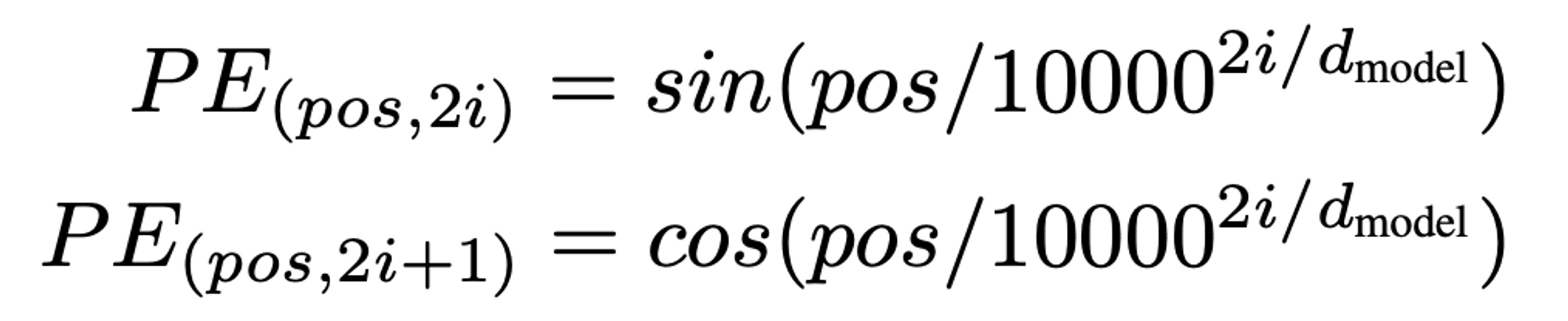
pos는 입력 문장에서 임베딩 벡터의 위치를 나타냅니다.
I am a student라는 문장에서 제가 am 이라는 단어를 [3, 0.2, 1, 0.7] 로 바꿨다면 am의 pos는 2가 되는 겁니다.
i는 임베딩 벡터 내의 차원을 의미합니다.
아래의 그림은 임베딩 벡터와 포지션 벡터의 합을 표현한 그림입니다.
왼쪽의 푸른색 매트릭스가 임베딩 매트릭스이고
오른쪽의 흑백 매트릭스가 Positional Encoding 매트릭스로 위의 식으로 계산한 매트릭스라고 볼 수 있습니다.

최종적으로는 두 개의 매트릭스를 summation합니다.
이 경우, 더하는 것이 아니라 concatanate 할 수도 있다고 합니다.
하지만 그렇게 하면 컴퓨팅량이 늘어나게 되고
Positional Encoding의 각 셀의 값으 그렇게 크지 않으므로 더해도 의미를 크게 해치지 않습니다.
아래의 블로그에서 트랜스포머의 Positional Encoding이 아주 잘 정리되어 있으니 참고하시면 좋을 것 같습니다.
트랜스포머(Transformer) 파헤치기—1. Positional Encoding
트랜스포머 Transformer Attention is All You Need Postional Encoding
www.blossominkyung.com
이렇게 포지셔널 인코딩 (Positional Encoding)까지 완료된 input 단어 토큰들은
본격적으로 셀프 어텐션을 거치게 됩니다.
감사합니다.
블레이즈 테크노트.
'머신러닝(Machine Learning)' 카테고리의 다른 글
| NLP 트랜스포머 네 번째, 멀티 헤드 어텐션 Multi-Head Attention 알아보기 (0) | 2023.08.01 |
|---|---|
| NLP 트랜스포머 세 번째, 셀프 어텐션 알아보기 (0) | 2023.07.30 |
| NLP 트랜스포머 첫 번째, RNN에서 트랜스포머로 (0) | 2023.07.24 |
| NMT(인공 신경망 기계 번역) Seq2Seq 에서 어텐션 메커니즘까지 정리 (0) | 2023.07.14 |
| NMT(인공신경망 기계 번역) 어텐션(Attention)이란? 기초 설명 (0) | 2023.07.13 |



