
안녕하세요
블레이즈 테크노트
블레이즈 입니다.

지난 포스팅
트랜스포머 네 번째, 멀티헤드 어텐션 알아보기에서 멀티 헤드 어텐션의 개념에 대해서 살펴보았습니다.
https://blazetechnote.tistory.com/24
NLP 트랜스포머 네 번째, 멀티 헤드 어텐션 Multi-Head Attention 알아보기
안녕하세요 블레이즈 테크노트 블레이즈 입니다. 지난 포스팅 트랜스포머 세 번째, 셀프 어텐션 알아보기에서 셀프 어텐션에 대한 기본적인 구조를 알아봤습니다. NLP 트랜스포머 세 번째, 셀프
blazetechnote.tistory.com
이번 포스팅은 트랜스포머 모델에서 사용되는
3종류의 멀티 헤드 어텐션을 살펴보고
어텐션 층 다음에 이어지는 피드 포워드 네트워크 (Feed Forward Network) 층도 확인해보도록 하겠습니다.
트랜스포머 모델에서 사용되는 어텐션 메커니즘은 기본적으로 Multi-head Self-Attention 입니다.
하지만 모델의 어느 위치에서 사용되느냐에 따라 조금씩 차이가 있습니다.

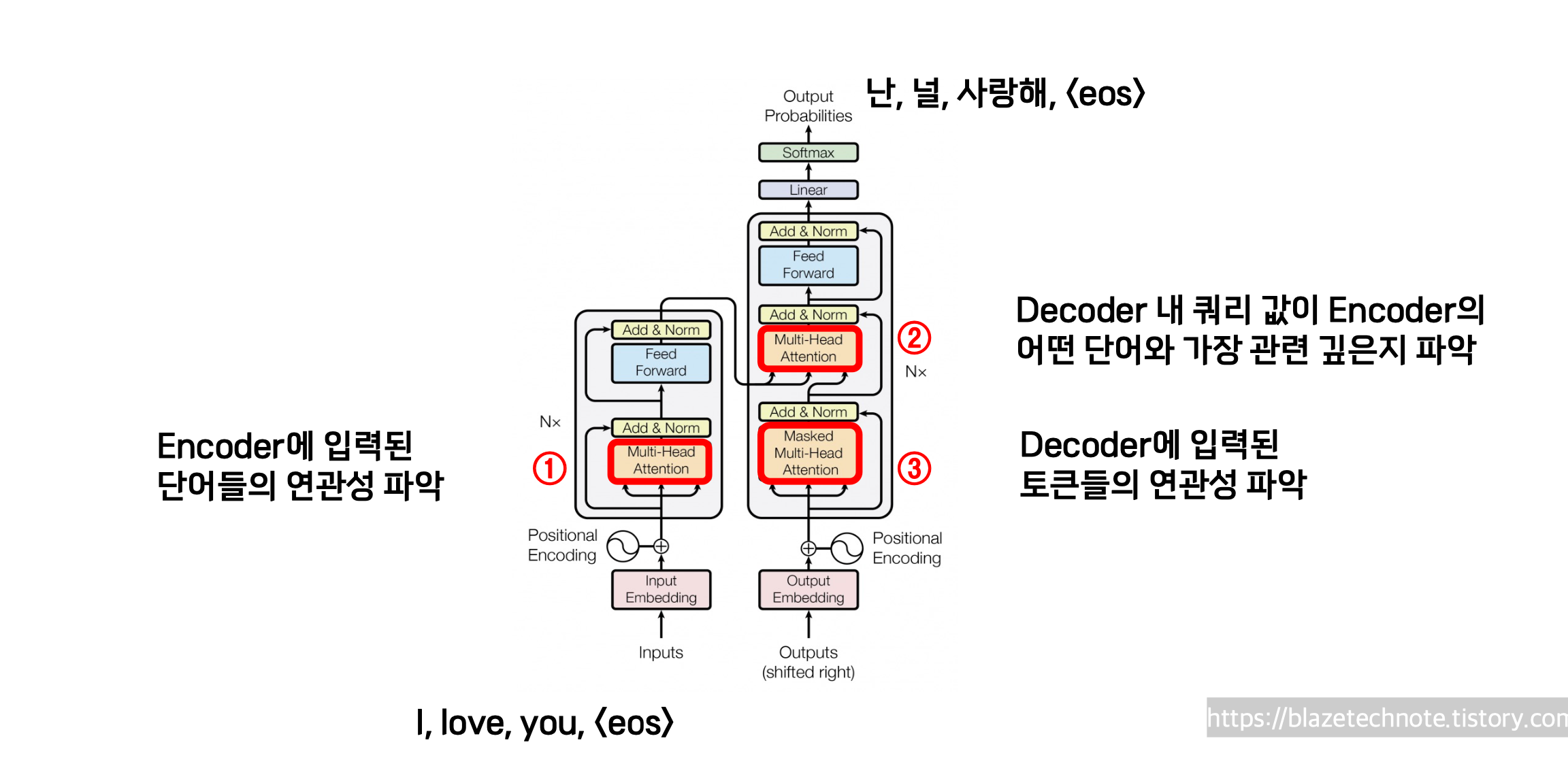
위 그림을 보시면 제가 1, 2, 3 표시를 했습니다.
1번은 인코더에서 사용되는 층입니다.
저희가 인풋을 넣으면 가장 먼저 거치게 되는 곳이죠.
그리고 2번과 3번은 디코더 내부에서 사용되는 어텐션 층입니다.
실제로 데이터가 흐르는 방향은 3번 -> 2번 이렇게 됩니다.

1번 어텐션은 인코더 내부의 셀프 어텐션입니다.
1번은 인풋으로 들어온 문장에 대한 Multi-Head Self-Attention입니다.
제가 지난 포스트에서 다뤘던 어텐션과 정확히 동일합니다.
2번 어텐션은 인코더-디코더 어텐션입니다.
2번 어텐션은 Q, K, V가 약간 다릅니다.
Q는 디코더의 인풋이고
K와 V는 인코더의 결과로 나온 key와 value 행렬이 됩니다.
예를 들어, I love you 라는 문장을 '난 널 사랑해'라는 문장으로 번역할 때
'난' 이라는 단어를 query로 하여
'난'과 'I' 'love' 'you' 라는 단어 사이의 관계를 파악하는 작업으로 생각할 수 있습니다.
마지막으로 3번 어텐션은 1번과 유사한 셀프 어텐션인데 추가적으로 Masking 이라는 과정이 추가되어 있습니다.
그 이유는 디코더의 셀프 어텐션의 경우
미래의 정보를 참조하여 어텐션 값을 얻지 않기 위해서 입니다.
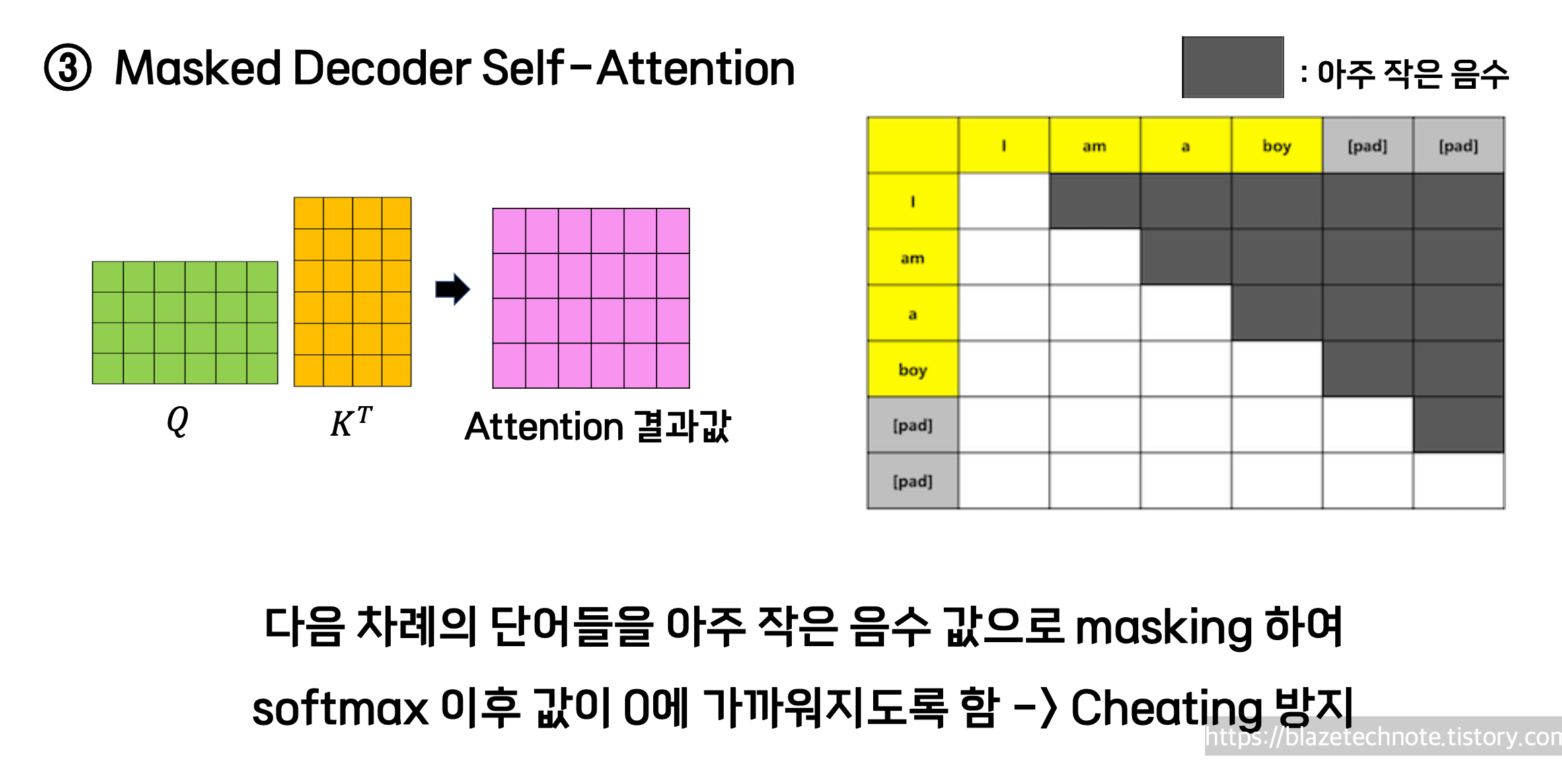
구체적으로 Masked Decoder Self-Attention 은
자기보다 뒷 부분의 토큰에 대하여 마이너스 무한대를 곱합니다.
그러면 그 토큰의 값이 음의 무한대가 되고
소프트맥스 softmax 함수를 취하여 어텐션 값이 0에 아주아주 가까운 값이 됩니다.
마지막으로 Position-Wise Feed-Forward Networks 에 대해 설명하겠습니다.
간단하게는 FFN 이라고도 하고 피드 포워드 네트워크 라고도 합니다.
아래의 그림을 보면 어텐션 층을 통과하고 나면 항상 이 FFN 층을 거치게 됩니다.

피드 포워드 네트워크는 멀티 헤드 어텐션에서 취합한 결과를 다양하게 해석하는데 도움을 줍니다.
특히 중간에 ReLU 함수를 거치기 때문에
비선형적인 정보를 취합하는데에도 효과가 있다고 알려져 있습니다.
구체적으로는 실제 코드의 Feed-Forward Network 부분을 참고하시면 더 이해가 잘 되실 겁니다.
위 링크로 들어가시면 제가 실제 논문의 코드를 리뷰한 포스팅이 있습니다:)

감사합니다.
블레이즈 테크노트
'머신러닝(Machine Learning)' 카테고리의 다른 글
| NLP 트랜스포머 코드 스터디 리뷰 common_attention.py (0) | 2023.09.01 |
|---|---|
| NLP 트랜스포머 코드 스터디 리뷰 common_layers.py (0) | 2023.08.28 |
| NLP 트랜스포머 코드 스터디 리뷰 transformer_layers.py (0) | 2023.08.23 |
| NLP 트랜스포머 코드 스터디 리뷰 (3) transformer.py (0) | 2023.08.21 |
| NLP 트랜스포머 코드 스터디 리뷰 (2) transformer.py (0) | 2023.08.19 |



