
안녕하세요
블레이즈 테크노트
블레이즈 입니다.

이번 포스트가 아마도 Attention is all you need 의 코드 리뷰 마지막이 될 것 같습니다.
그동안 트랜스포머 코드 스터디 리뷰 시리즈로 몇 백줄의 코드 리뷰를 해왔습니다.
모델의 아키텍쳐를 구현한 transformer.py는
1편, 2편, 3편 총 세 개의 포스트로 구성했습니다.
다음으로 transformer_layers.py 에 대해 리뷰를 했고요.
그 다음으로 common_layers.py에 대해 다루었습니다.
오늘 보실 common_attention.py는 트랜스포머의 햑심이 되는
multihead_attention에 대해서 다루는 모듈입니다.
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/layers/common_attention.py
compute_qkv 라는 함수가 있습니다.
이 함수는 Query, Key, Value를 계산하는 함수입니다.
def compute_qkv(query_antecedent,
memory_antecedent,
total_key_depth,
total_value_depth,
q_filter_width=1,
kv_filter_width=1,
q_padding="VALID",
kv_padding="VALID",
vars_3d_num_heads=0,
layer_collection=None):
"""Computes query, key and value.
Args:
query_antecedent: a Tensor with shape [batch, length_q, channels]
memory_antecedent: a Tensor with shape [batch, length_m, channels]
total_key_depth: an integer
total_value_depth: an integer
q_filter_width: An integer specifying how wide you want the query to be.
kv_filter_width: An integer specifying how wide you want the keys and values
to be.
q_padding: One of "VALID", "SAME" or "LEFT". Default is VALID: No padding.
kv_padding: One of "VALID", "SAME" or "LEFT". Default is VALID: No padding.
vars_3d_num_heads: an optional (if we want to use 3d variables)
layer_collection: A tensorflow_kfac.LayerCollection. Only used by the
KFAC optimizer. Default is None.
Returns:
q, k, v : [batch, length, depth] tensors
"""
if memory_antecedent is None:
memory_antecedent = query_antecedent
q = compute_attention_component(
query_antecedent,
total_key_depth,
q_filter_width,
q_padding,
"q",
vars_3d_num_heads=vars_3d_num_heads,
layer_collection=layer_collection)
k = compute_attention_component(
memory_antecedent,
total_key_depth,
kv_filter_width,
kv_padding,
"k",
vars_3d_num_heads=vars_3d_num_heads,
layer_collection=layer_collection)
v = compute_attention_component(
memory_antecedent,
total_value_depth,
kv_filter_width,
kv_padding,
"v",
vars_3d_num_heads=vars_3d_num_heads,
layer_collection=layer_collection)
return q, k, vdot_product_attention()라는 함수가 정의되어 있습니다.
이 함수는 기본적인 dot_product_attention을 계산합니다.
dot_product_attention 은 쿼리, 키, 밸류 매트릭스를 곱해주는 어텐션 계산 방법인데 보다 자세한 설명은 이 포스트를 참고해주세요.
def dot_product_attention(q,
k,
v,
bias,
dropout_rate=0.0,
image_shapes=None,
name=None,
make_image_summary=True,
save_weights_to=None,
dropout_broadcast_dims=None,
activation_dtype=None,
weight_dtype=None,
hard_attention_k=0,
gumbel_noise_weight=0.0):
"""Dot-product attention.
Args:
q: Tensor with shape [..., length_q, depth_k].
k: Tensor with shape [..., length_kv, depth_k]. Leading dimensions must
match with q.
v: Tensor with shape [..., length_kv, depth_v] Leading dimensions must
match with q.
bias: bias Tensor (see attention_bias())
dropout_rate: a float.
image_shapes: optional tuple of integer scalars.
see comments for attention_image_summary()
name: an optional string
make_image_summary: True if you want an image summary.
save_weights_to: an optional dictionary to capture attention weights
for visualization; the weights tensor will be appended there under
a string key created from the variable scope (including name).
dropout_broadcast_dims: an optional list of integers less than rank of q.
Specifies in which dimensions to broadcast the dropout decisions.
activation_dtype: Used to define function activation dtype when using
mixed precision.
weight_dtype: The dtype weights are stored in when using mixed precision
hard_attention_k: integer, if > 0 triggers hard attention (picking top-k)
gumbel_noise_weight: if > 0, apply Gumbel noise with weight
`gumbel_noise_weight` before picking top-k. This is a no op if
hard_attention_k <= 0.
Returns:
Tensor with shape [..., length_q, depth_v].
"""
with tf.variable_scope(
name, default_name="dot_product_attention", values=[q, k, v]) as scope:
logits = tf.matmul(q, k, transpose_b=True) # [..., length_q, length_kv]
if bias is not None:
bias = common_layers.cast_like(bias, logits)
logits += bias
# If logits are fp16, upcast before softmax
logits = maybe_upcast(logits, activation_dtype, weight_dtype)
weights = tf.nn.softmax(logits, name="attention_weights")
if hard_attention_k > 0:
weights = harden_attention_weights(weights, hard_attention_k,
gumbel_noise_weight)
weights = common_layers.cast_like(weights, q)
if save_weights_to is not None:
save_weights_to[scope.name] = weights
save_weights_to[scope.name + "/logits"] = logits
# Drop out attention links for each head.
weights = common_layers.dropout_with_broadcast_dims(
weights, 1.0 - dropout_rate, broadcast_dims=dropout_broadcast_dims)
if common_layers.should_generate_summaries() and make_image_summary:
attention_image_summary(weights, image_shapes)
return tf.matmul(weights, v)코드를 보시면
logits = tf.matmul(q, k, transpose_b = True) 로 되어 있습니다.
k 만 전치되어서 행렬곱을 계산하는 것이 dot-product 구현이 아주 잘 되어 있네요.
참고로 scaled-dot product attention의 식은 다음과 같습니다.
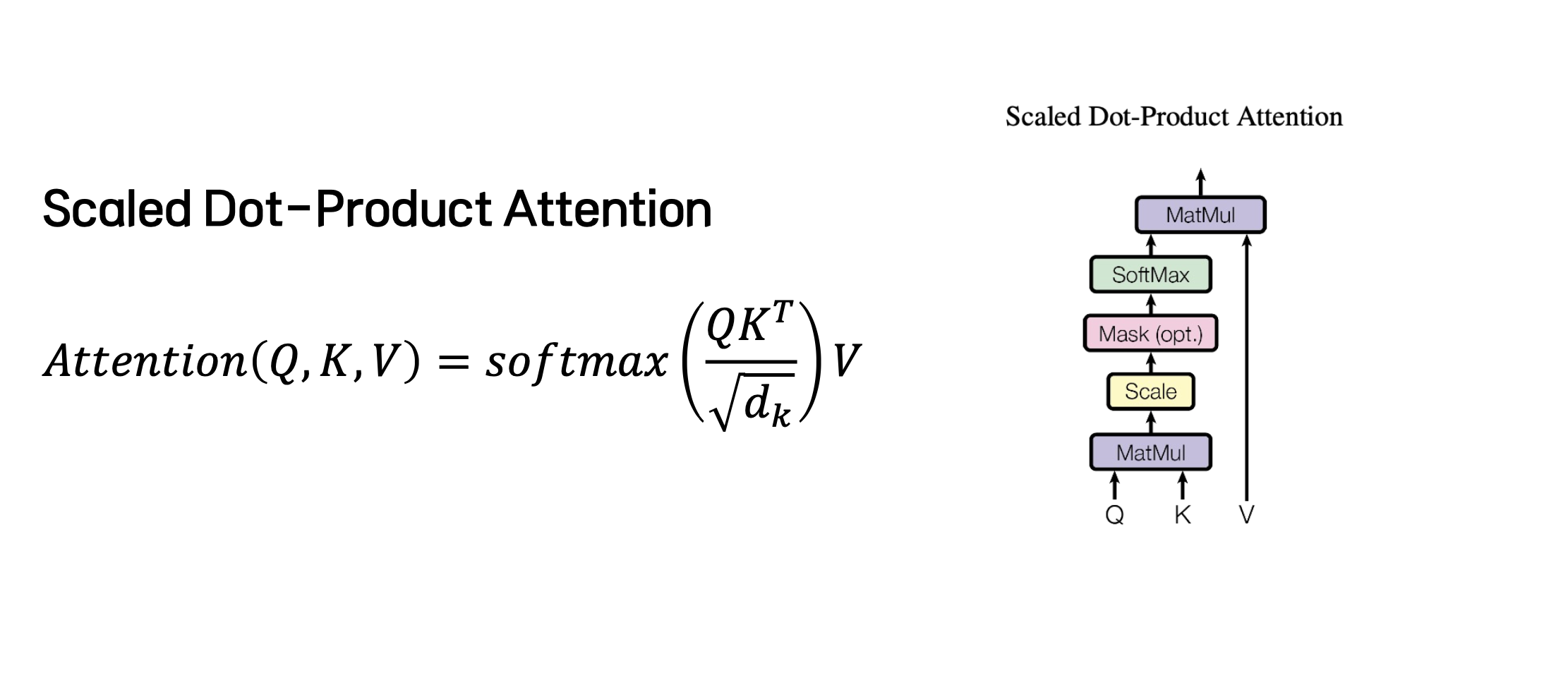
logits에 softmax를 취해서 weights를 얻었습니다.
weights = tf.nn.softmax(logits, name="attention_weights")
그 외에 더 강조할 부분이 있다면 harded_attention_weights()로 특정 부위의 어텐션 가중치를 높여줄 수도 있습니다.
다음으로 과적합 방지를 위해 dropout을 했습니다.
마지막으로 이 weights 에 v를 곱해서 리턴합니다.
return tf.matmul(weights, v)
다음으로 multihead_attention이라는 함수가 정의되어 있습니다.
멀티헤드 어텐션은 어텐션을 계산할 때 병렬화 계산을 취하는 것입니다.
멀티 헤드에 대한 자세한 개념은 여기에 나와 있습니다.
아래에 코드를 첨부했는데, 생각보다 엄청 기네요..!
def multihead_attention(query_antecedent,
memory_antecedent,
bias,
total_key_depth,
total_value_depth,
output_depth,
num_heads,
dropout_rate,
attention_type="dot_product",
max_relative_position=None,
heads_share_relative_embedding=False,
add_relative_to_values=False,
image_shapes=None,
block_length=128,
block_width=128,
q_filter_width=1,
kv_filter_width=1,
q_padding="VALID",
kv_padding="VALID",
cache=None,
gap_size=0,
num_memory_blocks=2,
name="multihead_attention",
save_weights_to=None,
make_image_summary=True,
dropout_broadcast_dims=None,
vars_3d=False,
layer_collection=None,
recurrent_memory=None,
chunk_number=None,
hard_attention_k=0,
gumbel_noise_weight=0.0,
max_area_width=1,
max_area_height=1,
memory_height=1,
area_key_mode="mean",
area_value_mode="sum",
training=True,
**kwargs):
"""Multihead scaled-dot-product attention with input/output transformations.
Args:
query_antecedent: a Tensor with shape [batch, length_q, channels]
memory_antecedent: a Tensor with shape [batch, length_m, channels] or None
bias: bias Tensor (see attention_bias())
total_key_depth: an integer
total_value_depth: an integer
output_depth: an integer
num_heads: an integer dividing total_key_depth and total_value_depth
dropout_rate: a floating point number
attention_type: a string, either "dot_product", "dot_product_relative",
"local_mask_right", "local_unmasked", "masked_dilated_1d",
"unmasked_dilated_1d", graph, or any attention function
with the signature (query, key, value, **kwargs)
max_relative_position: Maximum distance between inputs to generate
unique relation embeddings for. Only relevant
when using "dot_product_relative" attention.
heads_share_relative_embedding: boolean to share relative embeddings
add_relative_to_values: a boolean for whether to add relative component to
values.
image_shapes: optional tuple of integer scalars.
see comments for attention_image_summary()
block_length: an integer - relevant for "local_mask_right"
block_width: an integer - relevant for "local_unmasked"
q_filter_width: An integer specifying how wide you want the query to be.
kv_filter_width: An integer specifying how wide you want the keys and values
to be.
q_padding: One of "VALID", "SAME" or "LEFT". Default is VALID: No padding.
kv_padding: One of "VALID", "SAME" or "LEFT". Default is "VALID":
no padding.
cache: dict containing Tensors which are the results of previous
attentions, used for fast decoding. Expects the dict to contrain two
keys ('k' and 'v'), for the initial call the values for these keys
should be empty Tensors of the appropriate shape.
'k' [batch_size, 0, key_channels]
'v' [batch_size, 0, value_channels]
gap_size: Integer option for dilated attention to indicate spacing between
memory blocks.
num_memory_blocks: Integer option to indicate how many memory blocks to look
at.
name: an optional string.
save_weights_to: an optional dictionary to capture attention weights
for vizualization; the weights tensor will be appended there under
a string key created from the variable scope (including name).
make_image_summary: Whether to make an attention image summary.
dropout_broadcast_dims: an optional list of integers less than 4
specifying in which dimensions to broadcast the dropout decisions.
saves memory.
vars_3d: use 3-dimensional variables for input/output transformations
layer_collection: A tensorflow_kfac.LayerCollection. Only used by the
KFAC optimizer. Default is None.
recurrent_memory: An optional transformer_memory.RecurrentMemory, which
retains state across chunks. Default is None.
chunk_number: an optional integer Tensor with shape [batch] used to operate
the recurrent_memory.
hard_attention_k: integer, if > 0 triggers hard attention (picking top-k).
gumbel_noise_weight: if > 0, apply Gumbel noise with weight
`gumbel_noise_weight` before picking top-k. This is a no op if
hard_attention_k <= 0.
max_area_width: the max width allowed for an area.
max_area_height: the max height allowed for an area.
memory_height: the height of the memory.
area_key_mode: the mode for computing area keys, which can be "mean",
"concat", "sum", "sample_concat", and "sample_sum".
area_value_mode: the mode for computing area values, which can be either
"mean", or "sum".
training: indicating if it is in the training mode.
**kwargs (dict): Parameters for the attention function.
Caching:
WARNING: For decoder self-attention, i.e. when memory_antecedent == None,
the caching assumes that the bias contains future masking.
The caching works by saving all the previous key and value values so that
you are able to send just the last query location to this attention
function. I.e. if the cache dict is provided it assumes the query is of the
shape [batch_size, 1, hidden_dim] rather than the full memory.
Returns:
The result of the attention transformation. The output shape is
[batch_size, length_q, hidden_dim]
unless the cache dict is provided in which case only the last memory
position is calculated and the output shape is [batch_size, 1, hidden_dim]
Optionally returns an additional loss parameters (ex: load balance loss for
the experts) returned by the attention_type function.
Raises:
ValueError: if the key depth or value depth are not divisible by the
number of attention heads.
"""
if total_key_depth % num_heads != 0:
raise ValueError("Key depth (%d) must be divisible by the number of "
"attention heads (%d)." % (total_key_depth, num_heads))
if total_value_depth % num_heads != 0:
raise ValueError("Value depth (%d) must be divisible by the number of "
"attention heads (%d)." % (total_value_depth, num_heads))
vars_3d_num_heads = num_heads if vars_3d else 0
if layer_collection is not None:
if cache is not None:
raise ValueError("KFAC implementation only supports cache is None.")
if vars_3d:
raise ValueError("KFAC implementation does not support 3d vars.")
if recurrent_memory is not None:
if memory_antecedent is not None:
raise ValueError("Recurrent memory requires memory_antecedent is None.")
if cache is not None:
raise ValueError("Cache is not supported when using recurrent memory.")
if vars_3d:
raise ValueError("3d vars are not supported when using recurrent memory.")
if layer_collection is not None:
raise ValueError("KFAC is not supported when using recurrent memory.")
if chunk_number is None:
raise ValueError("chunk_number is required when using recurrent memory.")
with tf.variable_scope(name, default_name="multihead_attention",
values=[query_antecedent, memory_antecedent]):
if recurrent_memory is not None:
(
recurrent_memory_transaction,
query_antecedent, memory_antecedent, bias,
) = recurrent_memory.pre_attention(
chunk_number,
query_antecedent, memory_antecedent, bias,
)
if cache is None or memory_antecedent is None:
q, k, v = compute_qkv(query_antecedent, memory_antecedent,
total_key_depth, total_value_depth, q_filter_width,
kv_filter_width, q_padding, kv_padding,
vars_3d_num_heads=vars_3d_num_heads,
layer_collection=layer_collection)
if cache is not None:
if attention_type not in ["dot_product", "dot_product_relative"]:
# TODO(petershaw): Support caching when using relative position
# representations, i.e. "dot_product_relative" attention.
raise NotImplementedError(
"Caching is not guaranteed to work with attention types other than"
" dot_product.")
if bias is None:
raise ValueError("Bias required for caching. See function docstring "
"for details.")
if memory_antecedent is not None:
# Encoder-Decoder Attention Cache
q = compute_attention_component(query_antecedent, total_key_depth,
q_filter_width, q_padding, "q",
vars_3d_num_heads=vars_3d_num_heads)
k = cache["k_encdec"]
v = cache["v_encdec"]
else:
k = split_heads(k, num_heads)
v = split_heads(v, num_heads)
decode_loop_step = kwargs.get("decode_loop_step")
if decode_loop_step is None:
k = cache["k"] = tf.concat([cache["k"], k], axis=2)
v = cache["v"] = tf.concat([cache["v"], v], axis=2)
else:
# Inplace update is required for inference on TPU.
# Inplace_ops only supports inplace_update on the first dimension.
# The performance of current implementation is better than updating
# the tensor by adding the result of matmul(one_hot,
# update_in_current_step)
tmp_k = tf.transpose(cache["k"], perm=[2, 0, 1, 3])
tmp_k = inplace_ops.alias_inplace_update(
tmp_k, decode_loop_step, tf.squeeze(k, axis=2))
k = cache["k"] = tf.transpose(tmp_k, perm=[1, 2, 0, 3])
tmp_v = tf.transpose(cache["v"], perm=[2, 0, 1, 3])
tmp_v = inplace_ops.alias_inplace_update(
tmp_v, decode_loop_step, tf.squeeze(v, axis=2))
v = cache["v"] = tf.transpose(tmp_v, perm=[1, 2, 0, 3])
q = split_heads(q, num_heads)
if cache is None:
k = split_heads(k, num_heads)
v = split_heads(v, num_heads)
key_depth_per_head = total_key_depth // num_heads
if not vars_3d:
q *= key_depth_per_head**-0.5
additional_returned_value = None
if callable(attention_type): # Generic way to extend multihead_attention
x = attention_type(q, k, v, **kwargs)
if isinstance(x, tuple):
x, additional_returned_value = x # Unpack
elif attention_type == "dot_product":
if max_area_width > 1 or max_area_height > 1:
x = area_attention.dot_product_area_attention(
q, k, v, bias, dropout_rate, image_shapes,
save_weights_to=save_weights_to,
dropout_broadcast_dims=dropout_broadcast_dims,
max_area_width=max_area_width,
max_area_height=max_area_height,
memory_height=memory_height,
area_key_mode=area_key_mode,
area_value_mode=area_value_mode,
training=training)
else:
x = dot_product_attention(
q, k, v, bias, dropout_rate, image_shapes,
save_weights_to=save_weights_to,
make_image_summary=make_image_summary,
dropout_broadcast_dims=dropout_broadcast_dims,
activation_dtype=kwargs.get("activation_dtype"),
hard_attention_k=hard_attention_k,
gumbel_noise_weight=gumbel_noise_weight)
elif attention_type == "dot_product_relative":
x = dot_product_attention_relative(
q,
k,
v,
bias,
max_relative_position,
dropout_rate,
image_shapes,
save_weights_to=save_weights_to,
make_image_summary=make_image_summary,
cache=cache is not None,
allow_memory=recurrent_memory is not None,
hard_attention_k=hard_attention_k,
gumbel_noise_weight=gumbel_noise_weight)
elif attention_type == "dot_product_unmasked_relative_v2":
x = dot_product_unmasked_self_attention_relative_v2(
q,
k,
v,
bias,
max_relative_position,
dropout_rate,
image_shapes,
save_weights_to=save_weights_to,
make_image_summary=make_image_summary,
dropout_broadcast_dims=dropout_broadcast_dims,
heads_share_relative_embedding=heads_share_relative_embedding,
add_relative_to_values=add_relative_to_values)
elif attention_type == "dot_product_relative_v2":
x = dot_product_self_attention_relative_v2(
q,
k,
v,
bias,
max_relative_position,
dropout_rate,
image_shapes,
save_weights_to=save_weights_to,
make_image_summary=make_image_summary,
dropout_broadcast_dims=dropout_broadcast_dims,
heads_share_relative_embedding=heads_share_relative_embedding,
add_relative_to_values=add_relative_to_values)
elif attention_type == "local_within_block_mask_right":
x = masked_within_block_local_attention_1d(
q, k, v, block_length=block_length)
elif attention_type == "local_relative_mask_right":
x = masked_relative_local_attention_1d(
q,
k,
v,
block_length=block_length,
make_image_summary=make_image_summary,
dropout_rate=dropout_rate,
heads_share_relative_embedding=heads_share_relative_embedding,
add_relative_to_values=add_relative_to_values,
name="masked_relative_local_attention_1d")
elif attention_type == "local_mask_right":
x = masked_local_attention_1d(
q,
k,
v,
block_length=block_length,
make_image_summary=make_image_summary)
elif attention_type == "local_unmasked":
x = local_attention_1d(
q, k, v, block_length=block_length, filter_width=block_width)
elif attention_type == "masked_dilated_1d":
x = masked_dilated_self_attention_1d(q, k, v, block_length, block_width,
gap_size, num_memory_blocks)
else:
assert attention_type == "unmasked_dilated_1d"
x = dilated_self_attention_1d(q, k, v, block_length, block_width,
gap_size, num_memory_blocks)
x = combine_heads(x)
# Set last dim specifically.
x.set_shape(x.shape.as_list()[:-1] + [total_value_depth])
if vars_3d:
o_var = tf.get_variable(
"o", [num_heads, total_value_depth // num_heads, output_depth])
o_var = tf.cast(o_var, x.dtype)
o_var = tf.reshape(o_var, [total_value_depth, output_depth])
x = tf.tensordot(x, o_var, axes=1)
else:
x = common_layers.dense(
x, output_depth, use_bias=False, name="output_transform",
layer_collection=layer_collection)
if recurrent_memory is not None:
x = recurrent_memory.post_attention(recurrent_memory_transaction, x)
if additional_returned_value is not None:
return x, additional_returned_value
return x
1.
if total_key_depth % num_heads != 0:
raise ValueError("Key depth (%d) must be divisible by the number of "
"attention heads (%d)." % (total_key_depth, num_heads))
를 보시면 num_head는 total_key_depth의 약수여야 한다는 것을 알 수 있습니다.
2.
k = split_heads(k, num_heads)
v = split_heads(v, num_heads)
를 보면 key와 value를 헤드의 개수로 나눠줍니다.
이렇게 헤드를 나누면 병렬화하여 계산할 수 있습니다.
중간 중간 캐시에서 k와 v를 가져오는 구문은 생략하도록 하겠습니다.
3.
q = split_heads(q, num_heads)
key_depth_per_head = total_key_depth // num_heads

4.
if not vars_3d:
q *= key_depth_per_head**-0.5
이 식은 키의 디멘션의 제곱근 으로 q 를 나눠주는 계산이므로 스케일링에 해당합니다.
5.
elif attention_type == "dot_product":
if max_area_width > 1 or max_area_height > 1:
x = area_attention.dot_product_area_attention(
q, k, v, bias, dropout_rate, image_shapes,
save_weights_to=save_weights_to,
dropout_broadcast_dims=dropout_broadcast_dims,
max_area_width=max_area_width,
max_area_height=max_area_height,
memory_height=memory_height,
area_key_mode=area_key_mode,
area_value_mode=area_value_mode,
training=training)
어텐션 타입이 닷-프로덕트 이고 if max_area_width > 1 or max_area_height > 1: 인 경우에 해당합니다.
그러나 일반적으로 두 값은 1입니다. 1보다 큰 경우 해당 영역의 어텐션을 계산하는 과정을 거칩니다.
6.
else:
x = dot_product_attention(
q, k, v, bias, dropout_rate, image_shapes,
save_weights_to=save_weights_to,
make_image_summary=make_image_summary,
dropout_broadcast_dims=dropout_broadcast_dims,
activation_dtype=kwargs.get("activation_dtype"),
hard_attention_k=hard_attention_k,
gumbel_noise_weight=gumbel_noise_weight)
두 값이 모두 1 이하인 경우 일반적인 dot_product_attention이 수행됩니다.
그 뒤의 elif 문들은 모두 다양한 attention_type에 따라 작업을 수행합니다.

7.
x = combine_heads(x)
다음으로 이렇게 구한 어텐션 값들은 각각의 헤드에 대해서 구한 것이므로 이를 합쳐줍니다.
8.
x.set_shape(x.shape.as_list()[:-1] + [total_value_depth])
이 부분은 결과 텐서 x의 모양(shape)을 명시적으로 설정합니다.
x.shape.as_list()[:-1]는 x의 마지막 차원을 제외한 모든 차원의 크기를 리스트 형태로 가져옵니다.
그리고 이 리스트에 total_value_depth를 추가함으로써 x의 마지막 차원의 크기를 total_value_depth로 설정합니다.
이렇게 함으로써 결과 텐서의 마지막 차원이 원하는 크기를 가지도록 명시적으로 설정합니다.
9.
x = common_layers.dense(
x, output_depth, use_bias=False, name="output_transform",
layer_collection=layer_collection)
이 dense() 는 full connected layer 라고 불립니다.
이 함수를 통해 여러 헤드에서 각각 뽑힌 정보를 한 번에 통합합니다.
그리고 다음 레이어로 output을 전달할 때 차원을 조절하는 역할도 합니다.

이렇게 multihead_attention() 까지 보니 트랜스포머 논문인
attention is all you need에서 발표된 코드의 중심내용은 거의 다 살펴본 것 같습니다.
정말 뿌듯하네요.
감사합니다.

블레이즈 테크 노트
'머신러닝(Machine Learning)' 카테고리의 다른 글
| NLP BERT 모델 이해하기 (1) 트랜스포머로부터 (0) | 2023.09.10 |
|---|---|
| 2023 서울대학교 컴퓨팅 프론티어 여름학교 (0) | 2023.09.03 |
| NLP 트랜스포머 코드 스터디 리뷰 common_layers.py (0) | 2023.08.28 |
| NLP 트랜스포머 다섯 번째, 여러 종류의 멀티헤드 어텐션과 피드 포워드 네트워크 FFN (0) | 2023.08.26 |
| NLP 트랜스포머 코드 스터디 리뷰 transformer_layers.py (0) | 2023.08.23 |



